Let us talk about healthcare data pipelines. Running high volume payer processing pipelines is a lot like hosting a mandatory potluck dinner for a group of deeply eccentric people with severe and conflicting dietary restrictions. Each payer behaves with maddening uniqueness. One payer bursts through the door, demanding an entire roasted pig, which they intend to consume in three minutes flat. This requires massive, short-lived computational horsepower. Another payer arrives with a single boiled pea and proceeds to chew it methodically for the next five hours, requiring a small but agonizingly persistent trickle of processing power.
On top of this culinary nightmare, there are strict rules of etiquette. You absolutely must digest the member data before you even look at the claims data. Eligibility files must be validated before anyone is allowed to touch the dessert tray of downstream jobs. The workload is not just heavy. It is incredibly uneven and delightfully complicated.
Buying folding chairs for a banquet
On paper, Amazon Web Services managed Auto Scaling Mechanisms should fix this problem. They are designed to look at a growing pile of work and automatically hire more help. But applying generic auto scaling to healthcare pipelines is like a restaurant manager seeing a line out the door and solving the problem by buying fifty identical plastic folding chairs.
The manager does not care that one guest needs a high chair and another requires a reinforced steel bench. Auto scaling reacts to the generic brute force of the system load. It cannot look at a specific payer and tailor the compute shape to fit their weird eating habits. It cannot enforce the strict social hierarchy of job priorities. It scales the infrastructure, but it completely fails to scale the intention.
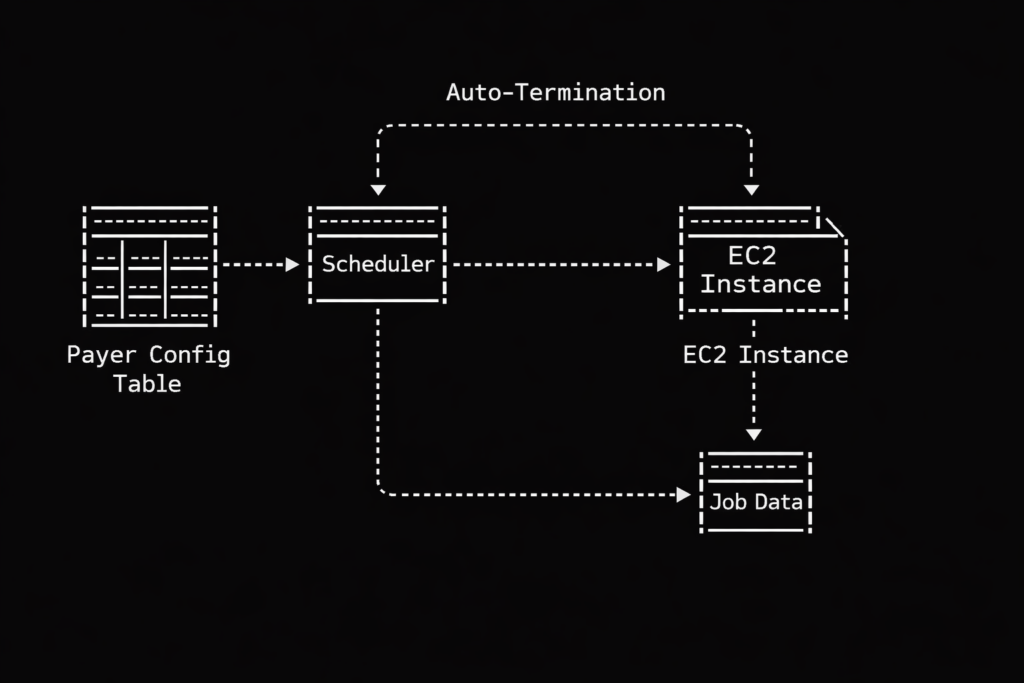
This is why we abandoned the generic approach and built our own dynamic EC2 provisioning system. Instead of maintaining a herd of generic servers waiting around for something to do, we create bespoke servers on demand based on a central configuration table.
The ruthless nightclub bouncer of job scheduling
Let us look at how this actually works regarding prioritization. Our system relies on that central configuration table to dictate order. Think of this table as the guest list at an obnoxiously exclusive nightclub. Our scheduler acts as the ruthless bouncer.
When jobs arrive at the queue, the bouncer checks the list. Member data? Right this way to the VIP lounge, sir. Claims data? Stand on the curb behind the velvet rope until the members are comfortably seated. Generic auto scaling has no native concept of this social hierarchy. It just sees a mob outside the club and opens the front doors wide. Our dynamic approach gives us perfect, tyrannical control over who gets processed first, ensuring our pipelines execute in a beautifully deterministic way. We spin up exactly the compute we specify, exactly when we want it.
Leaving your car running in the garage
Then there is the financial absurdity of warm pools. Standard auto scaling often relies on keeping a baseline of idle instances warm and ready, just in case a payer decides to drop a massive batch of files at two in the morning.
Keeping idle servers running is the technological equivalent of leaving your car engine idling in the closed garage all night just in case you get a sudden craving for a carton of milk at dawn. It is expensive, it is wasteful, and it makes you look a bit foolish when the AWS bill arrives.
Our dynamic system operates with a baseline of zero. We experience one hundred percent burst efficiency because we only pay for the exact compute we use, precisely when we use it. Cost savings happen naturally when you refuse to pay for things that are sitting around doing nothing.
A delightfully brutal server lifecycle
The operational model we ended up with is almost comically simple compared to traditional methods. A generic scaling group requires complex scaling policies, tricky cooldown periods, and endless tweaking of CloudWatch alarms. It is like managing a highly sensitive, moody teenager.
Our dynamic EC2 model is wonderfully ruthless. We create the instance and inject it with a single, highly specific purpose via a startup script. The instance wakes up, processes the healthcare data with absolute precision, and then politely self destructs so it stops billing us. They are the mayflies of the cloud computing world. They live just long enough to do their job, and then they vanish. There are no orphaned instances wandering the cloud.
This dynamic provisioning model has fundamentally altered how we digest payer workloads. We have somehow achieved a weird but perfect holy grail of cloud architecture. We get the granular flexibility of serverless functions, the raw, unadulterated horsepower of dedicated EC2 instances, and the stingy cost efficiency of a pure event-driven design.
If your processing jobs vary wildly from payer to payer, and if you care deeply about enforcing priorities without burning money on idle metal, building a disposable compute army might be exactly what your architecture is missing. We said goodbye to our idle servers, and honestly, we do not miss them at all.
The shortcuts I use on every project now, after learning that scale mostly changes the bill, not the mistakes.
Let me tell you how this started. I used to measure my productivity by how many AWS services I could haphazardly stitch together in a single afternoon. Big mistake.
One night, I was deploying what should have been a boring, routine feature. Nothing fancy. Just basic plumbing. Six hours later, I was still babysitting the deployment, clicking through the AWS console like a caffeinated lab rat, re-running scripts, and manually patching up tiny human errors.
That is when the epiphany hit me like a rogue server rack. I was not slow because AWS is a labyrinth of complexity. I was slow because I was doing things manually that AWS already knows how to do in its sleep.
The patterns below did not come from sanitized tutorials. They were forged in the fires of shipping systems under immense pressure and desperately wanting my weekends back.
Event-driven everything and absolutely no polling
If you are polling, you are essentially paying Jeff Bezos for the privilege of wasting your own time. Polling is the digital equivalent of sitting in the backseat of a car and constantly asking, “Are we there yet?” every five seconds.
AWS is an event machine. Treat it like one. Instead of writing cron jobs that anxiously ask the database if something changed, just let AWS tap you on the shoulder when it actually happens.
Where this shines:
File uploads
Database updates
Infrastructure state changes
Cross-account automation
Example of reacting to an S3 upload instantly:
def lambda_handler(event, context):
for record in event['Records']:
bucket_name = record['s3']['bucket']['name']
object_key = record['s3']['object']['key']
# Stop asking if the file is there. AWS just handed it to you.
trigger_completely_automated_workflow(bucket_name, object_key)
No loops. No waiting. Just action.
Pro tip: Event-driven systems fail less frequently simply because they do less work. They are the lazy geniuses of the cloud world.
Immutable deployments or nothing
SSH is not a deployment strategy. It is a desperate cry for help.
If your deployment plan involves SSH, SCP, or uttering the cursed phrase “just this one quick change in production”, you do not have a system. You have a fragile ecosystem built on hope and duct tape. I stopped “fixing” servers years ago. Now, I just murder them and replace them with fresh clones.
The pattern is brutally simple:
Build once
Deploy new
Destroy old
Example of launching a new EC2 version programmatically:
It is like doing open-heart surgery. Instead of trying to fix the heart while the patient is running a marathon, just build a new patient with a healthy heart and disintegrate the old one. When something breaks, I do not debug the server. I debug the build process. That is where the real parasites live.
Infrastructure as code for the forgettable things
Most teams only use IaC for the big, glamorous stuff. VPCs. Kubernetes clusters. Massive databases.
This is completely backwards. It is like wearing a bespoke tuxedo but forgetting your underwear. The small, forgettable resources are the ones that will inevitably bite you when you least expect it.
If it matters in production, it lives in code. No exceptions.
Let Step Functions own the flow
Early in my career, I crammed all my business logic into Lambdas. Retries, branching, timeouts, bizarre edge cases. I treated them like a digital junk drawer.
I do not do that anymore. Lambdas should be as dumb and fast as a golden retriever chasing a tennis ball.
The new rule: One Lambda equals one job. If you need a workflow, use Step Functions. They are the micromanaging middle managers your architecture desperately needs.
This separation makes debugging highly visual, makes retries explicit, and makes onboarding the new guy infinitely less painful. Your future self will thank you.
Kill cron jobs and use managed schedulers
Cron jobs are perfectly fine until they suddenly are not.
They are the ghosts of your infrastructure. They are completely invisible until they fail, and when they do fail, they die in absolute silence like a ninja with a sudden heart condition. AWS gives you managed scheduling. Just use it.
Why this is fundamentally faster:
Central visibility
Built-in retries
IAM-native permissions
Example of creating a scheduled rule:
eventbridge.put_rule(
Name="TriggerNightlyChaos",
ScheduleExpression="cron(0 2 * * ? *)",
State="ENABLED",
Description="Wakes up the system when nobody is looking"
)
Automation should be highly observable. Cron jobs are just waiting in the dark to ruin your Tuesday.
Bake cost controls into automation
Speed without cost awareness is just a highly efficient way to bankrupt your employer. The fastest teams I have ever worked with were not just shipping fast. They were failing cheaply.
What I automate now with the ruthlessness of a debt collector:
Budget alerts
Resource TTLs
Auto-shutdowns for non-production environments
Example of tagging resources with an expiration date:
Leaving resources without an owner or an expiration date is like leaving the stove on, except this stove bills you by the millisecond. Anything without a TTL is just technical debt waiting to invoice you.
A quote I live by: “Automation does not cut costs by magic. It cuts costs by quietly preventing the expensive little mistakes humans call normal.”
The death of the cloud hero
These patterns did not make me faster because they are particularly clever. They made me faster because they completely eliminated the need to make decisions.
Less clicking. Less remembering. Absolutely zero heroics.
If you want to move ten times faster on AWS, stop asking what to build next. Once automation is in charge, real speed usually arrives as work you no longer have to remember.
I was staring at our AWS bill at two in the morning, nursing my third cup of coffee, when I realized something that should have been obvious months earlier. We were paying more to distribute our traffic than to process it. Our Application Load Balancer, that innocent-looking service that simply forwards packets from point A to point B, was consuming $3,900 every month. That is $46,800 a year. For a traffic cop. A very expensive traffic cop that could not even handle our peak loads without breaking into a sweat.
The particularly galling part was that we had accepted this as normal. Everyone uses AWS load balancers, right? They are the standard, the default, the path of least resistance. It is like paying rent for an apartment you only use to store your shoes. Technically functional, financially absurd.
So we did what any reasonable engineering team would do at that hour. We started googling. And that is how we discovered IPVS, a technology so old that half our engineering team had not been born when it was first released. IPVS stands for IP Virtual Server, which sounds like something from a 1990s hacker movie, and honestly, that is not far off. It was written in 1998 by a fellow named Wensong Zhang, who presumably had no idea that twenty-eight years later, a group of bleary-eyed engineers would be using his code to save more than forty-six thousand dollars a year.
The expensive traffic cop
To understand why we were so eager to jettison our load balancer, you need to understand how AWS pricing works. Or rather, how it accumulates like barnacles on the hull of a ship, slowly dragging you down until you wonder why you are moving so slowly.
An Application Load Balancer costs $0.0225 per hour. That sounds reasonable, about sixteen dollars a month. But then there are LCUs, or Load Balancer Capacity Units, which charge you for every new connection, every rule evaluation, every processed byte. It is like buying a car and then discovering you have to pay extra every time you turn the steering wheel.
In practice, this meant our ALB was consuming fifteen to twenty percent of our entire infrastructure budget. Not for compute, not for storage, not for anything that actually creates value. Just for forwarding packets. It was the technological equivalent of paying a butler to hand you the remote control.
The ALB also had some architectural quirks that made us scratch our heads. It terminated TLS, which sounds helpful until you realize we were already terminating TLS at our ingress. So we were decrypting traffic, then re-encrypting it, then decrypting it again. It was like putting on a coat to go outside, then taking it off and putting on another identical coat, then finally going outside. The security theater was strong with this one.
A trip to 1999
I should confess that when we started this project, I had no idea what IPVS even stood for. I had heard it mentioned in passing by a colleague who used to work at a large Chinese tech company, where apparently everyone uses it. He described it with the kind of reverence usually reserved for vintage wine or classic cars. “It just works,” he said, which in engineering terms is the highest possible praise.
IPVS, I learned, lives inside the Linux kernel itself. Not in a container, not in a microservice, not in some cloud-managed abstraction. In the actual kernel. This means when a packet arrives at your server, the kernel looks at it, consults its internal routing table, and forwards it directly. No context switches, no user-space handoffs, no “let me ask my manager” delays. Just pure, elegant packet forwarding.
The first time I saw it in action, I felt something I had not felt in years of cloud engineering. I felt wonder. Here was code written when Bill Clinton was president, when the iPod was still three years away, when people used modems to connect to the internet. And it was outperforming a service that AWS charges thousands of dollars for. It was like discovering that your grandfather’s pocket watch keeps better time than your smartwatch.
How the magic happens
Our setup is almost embarrassingly simple. We run a DaemonSet called ipvs-router on dedicated, tiny nodes in each Availability Zone. Each pod does four things, and it does them with the kind of efficiency that makes you question everything else in your stack.
First, it claims an Elastic IP using kube-vip, a CNCF project that lets Kubernetes pods take ownership of spare EIPs. No AWS load balancer required. The pod simply announces “this IP is mine now”, and the network obliges. It feels almost rude how straightforward it is.
Second, it programs IPVS in the kernel. IPVS builds an L4 load-balancing table that forwards packets at line rate. No proxies, no user-space hops. The kernel becomes your load balancer, which is a bit like discovering your car engine can also make excellent toast. Unexpected, but delightful.
Third, it syncs with Kubernetes endpoints. A lightweight controller watches for new pods, and when one appears, IPVS adds it to the rotation in less than a hundred milliseconds. Scaling feels instantaneous because, well, it basically is.
But the real trick is the fourth thing. We use something called Direct Server Return, or DSR. Here is how it works. When a request comes in, it travels from the client to IPVS to the pod. But the response goes directly from the pod back to the client, bypassing the load balancer entirely. The load balancer never sees response traffic. That is how we get ten times the throughput. It is like having a traffic cop who only directs cars into the city but does not care how they leave.
The code that makes it work
Here is what our DaemonSet looks like. I have simplified it slightly for readability, but this is essentially what runs in our production cluster:
The key here is hostNetwork: true, which gives the pod direct access to the host’s network stack. Combined with the NET_ADMIN capability, this allows IPVS to manipulate the kernel’s routing tables directly. It requires a certain level of trust in your containers, but then again, so does running a load balancer in the first place.
We also use a custom controller to sync Kubernetes endpoints with IPVS. Here is the core logic:
# Simplified endpoint sync logic
def sync_endpoints(service_name, namespace):
# Get current endpoints from Kubernetes
endpoints = k8s_client.list_namespaced_endpoints(
namespace=namespace,
field_selector=f""metadata.name={service_name}""
)
# Extract pod IPs
pod_ips = []
for subset in endpoints.items[0].subsets:
for address in subset.addresses:
pod_ips.append(address.ip)
# Build IPVS rules using ipvsadm
for ip in pod_ips:
subprocess.run([
""ipvsadm"", ""-a"", ""-t"",
f""{VIP}:443"", ""-r"", f""{ip}:443"", ""-g""
])
# The -g flag enables Direct Server Return (DSR)
return len(pod_ips)
The numbers that matter
Let me tell you about the math, because the math is almost embarrassing for AWS. Our old ALB took about five milliseconds to set up a new connection. IPVS takes less than half a millisecond. That is not an improvement. That is a different category of existence. It is the difference between walking to the shops and being teleported there.
While our ALB would start getting nervous around one hundred thousand concurrent connections, IPVS just does not. It could handle millions. The only limit is how much memory your kernel has, which in our case meant we could have hosted the entire internet circa 2003 without breaking a sweat.
In terms of throughput, our ALB topped out around 2.5 gigabits per second. IPVS saturates the 25-gigabit NIC on our c7g.medium instances. That is ten times the throughput, for those keeping score at home. The load balancer stopped being the bottleneck, which was refreshing because previously it had been like trying to fill a swimming pool through a drinking straw.
But the real kicker is the cost. Here is the breakdown. We run one c7g.medium spot instance per availability zone, three zones total. Each costs about $0.017 per hour. That is $0.051 per hour for compute. We also have three Elastic IPs at $0.005 per hour each, which is $0.015 per hour. With Direct Server Return, outbound transfer costs are effectively zero because responses bypass the load balancer entirely.
The total? A mere $0.066 per hour. Divide that among three availability zones, and you’re looking at roughly $0.009 per hour per zone. That’s nine-tenths of a cent per hour. Let’s not call it optimization, let’s call it a financial exorcism. We went from shelling out $3,900 a month to a modest $48. The savings alone could probably afford a very capable engineer’s caffeine habit.
But what about L7 routing
At this point, you might be raising a valid objection. IPVS is dumb L4. It does not inspect HTTP headers, it does not route based on gRPC metadata, and it does not care about your carefully crafted REST API conventions. It just forwards packets based on IP and port. It is the postal worker of the networking world. Reliable, fast, and utterly indifferent to what is in the envelope.
This is where we layer in Envoy, because intelligence should live where it makes sense. Here is how the request flow works. A client connects to one of our Elastic IPs. IPVS forwards that connection to a random healthy pod. Inside that pod, an Envoy sidecar inspects the HTTP/2 headers or gRPC metadata and routes to the correct internal service.
The result is L4 performance at the edge and L7 intelligence at the pod. We get the speed of kernel-level packet forwarding combined with the flexibility of modern service mesh routing. It is like having a Formula 1 engine in a car that also has comfortable seats and a good sound system. Best of both worlds. Our Envoy configuration looks something like this:
I should mention that our first attempt did not go smoothly. In fact, it went so poorly that we briefly considered pretending the whole thing had never happened and going back to our expensive ALBs.
The problem was DNS. We pointed our api.ourcompany.com domain at the new Elastic IPs, and then we waited. And waited. And nothing happened. Traffic was still going to the old ALB. It turned out that our DNS provider had a TTL of one hour, which meant that even after we updated the record, most clients were still using the old IP address for, well, an hour.
But that was not the real problem. The real problem was that we had forgotten to update our health checks. Our monitoring system was still pinging the old ALB’s health endpoint, which was now returning 404s because we had deleted the target group. So our alerts were going off, our pagers were buzzing, and our on-call engineer was having what I can only describe as a difficult afternoon.
We fixed it, of course. Updated the health checks, waited for DNS to propagate, and watched as traffic slowly shifted to the new setup. But for about thirty minutes, we were flying blind, which is not a feeling I recommend to anyone who values their peace of mind.
Deploying this yourself
If you are thinking about trying this yourself, the good news is that it is surprisingly straightforward. The bad news is that you will need to know your way around Kubernetes and be comfortable with the idea of pods manipulating kernel networking tables. If that sounds terrifying, perhaps stick with your ALB. It is expensive, but it is someone else’s problem.
Here is the deployment process in a nutshell. First, deploy the DaemonSet. Then allocate some spare Elastic IPs in your subnet. There is a particular quirk in AWS networking that can ruin your afternoon: the source/destination check. By default, EC2 instances are configured to reject traffic that does not match their assigned IP address. Since our setup explicitly relies on handling traffic for IP addresses that the instance does not technically ‘own’ (our Virtual IPs), AWS treats this as suspicious activity and drops the packets. You must disable the source/destination check on any instance running these router pods. It is a simple checkbox in the console, but forgetting it is the difference between a working load balancer and a black hole. The pods will auto-claim them using kube-vip. Also, ensure your worker node IAM roles have permission to reassociate Elastic IPs, or your pods will shout into the void without anyone listening. Update your DNS to point at the new IPs, using latency-based routing if you want to be fancy. Then watch as your ALB target group drains, and delete the ALB next week after you are confident everything is working.
The whole setup takes about three hours the first time, and maybe thirty minutes if you do it again. Three hours of work for $46,000 per year in savings. That is $15,000 per hour, which is not a bad rate by anyone’s standards.
What we learned about Cloud computing
Three months after we made the switch, I found myself at an AWS conference, listening to a presentation about their newest managed load balancing service. It was impressive, all machine learning and auto-scaling and intelligent routing. It was also, I calculated quietly, about four hundred times more expensive than our little IPVS setup.
I did not say anything. Some lessons are better learned the hard way. And as I sat there, sipping my overpriced conference coffee, I could not help but smile.
AWS managed services are built for speed of adoption and lowest-common-denominator use cases. They are not built for peak efficiency, extreme performance, or cost discipline. For foundational infrastructure like load balancing, a little DIY unlocks exponential gains.
The embarrassing truth is that we should have done this years ago. We were so accustomed to reaching for managed services that we never stopped to ask whether we actually needed them. It took a 2 AM coffee-fueled bill review to make us question the assumptions we had been carrying around.
Sometimes the future of cloud computing looks a lot like 1999. And honestly, that is exactly what makes it beautiful. There is something deeply satisfying about discovering that the solution to your expensive modern problem was solved decades ago by someone working on a much simpler internet, with much simpler tools, and probably much more sleep.
Wensong Zhang, wherever you are, thank you. Your code from 1998 is still making engineers happy in 2026. That is not a bad legacy for any piece of software.
The author would like to thank his patient colleagues who did not complain (much) during the DNS propagation incident, and the kube-vip maintainers who answered his increasingly desperate questions on Slack.
I have spent the better part of three years wrestling with Google Cloud Platform, and I am still not entirely convinced it wasn’t designed by a group of very clever people who occasionally enjoy a quiet laugh at the rest of us. The thing about GCP, you see, is that it works beautifully right up until the moment it doesn’t. Then it fails with such spectacular and Byzantine complexity that you find yourself questioning not just your career choices but the fundamental nature of causality itself.
My first encounter with Cloud Build was typical of this experience. I had been tasked with setting up a CI/CD pipeline for a microservices architecture, which is the modern equivalent of being told to build a Swiss watch while someone steadily drops marbles on your head. Jenkins had been our previous solution, a venerable old thing that huffed and puffed like a steam locomotive and required more maintenance than a Victorian greenhouse. Cloud Build promised to handle everything serverlessly, which is a word that sounds like it ought to mean something, but in practice simply indicates you won’t know where your code is running and you certainly won’t be able to SSH into it when things go wrong.
The miracle, when it arrived, was decidedly understated. I pushed some poorly written Go code to a repository and watched as Cloud Build sprang into life like a sleeper agent receiving instructions. It ran my tests, built a container, scanned it for vulnerabilities, and pushed it to storage. The whole process took four minutes and cost less than a cup of tea. I sat there in my home office, the triumph slowly dawning, feeling rather like a man who has accidentally trained his cat to make coffee. I had done almost nothing, yet everything had happened. This is the essential GCP magic, and it is deeply unnerving.
The vulnerability scanner is particularly wonderful in that quietly horrifying way. It examines your containers and produces a list of everything that could possibly go wrong, like a pilot’s pre-flight checklist written by a paranoid witchfinder general. On one memorable occasion, it flagged a critical vulnerability in a library I wasn’t even aware we were using. It turned out to be nested seven dependencies deep, like a Russian doll of potential misery. Fixing it required updating something else, which broke something else, which eventually led me to discover that our entire authentication layer was held together by a library last maintained in 2018 by someone who had subsequently moved to a commune in Oregon. The scanner was right, of course. It always is. It is the most anxious and accurate employee you will ever meet.
Google Kubernetes Engine or how I learned to stop worrying and love the cluster
If Cloud Build is the efficient butler, GKE is the robot overlord you find yourself oddly grateful to. My initial experience with Kubernetes was self-managed, which taught me many things, primarily that I do not have the temperament to manage Kubernetes. I spent weeks tuning etcd, debugging network overlays, and developing what I can only describe as a personal relationship with a persistent volume that refused to mount. It was less a technical exercise and more a form of digitally enhanced psychotherapy.
GKE’s Autopilot mode sidesteps all this by simply making the nodes disappear. You do not manage nodes. You do not upgrade nodes. You do not even, strictly speaking, know where the nodes are. They exist in the same conceptual space as socks that vanish from laundry cycles. You request resources, and they materialise, like summoning a very specific and obliging genie. The first time I enabled Autopilot, I felt I was cheating somehow, as if I had been given the answers to an exam I had not revised for.
The real genius is Workload Identity, a feature that allows pods to access Google services without storing secrets. Before this, secret management was a dark art involving base64 encoding and whispered incantations. We kept our API keys in Kubernetes secrets, which is rather like keeping your house keys under the doormat and hoping burglars are too polite to look there. Workload Identity removes all this by using magic, or possibly certificates, which are essentially the same thing in cloud computing. I demonstrated it to our security team, and their reaction was instructive. They smiled, which security people never do, and then they asked me to prove it was actually secure, which took another three days and several diagrams involving stick figures.
Istio integration completes the picture, though calling it integration suggests a gentle handshake when it is more like being embraced by a very enthusiastic octopus. It gives you observability, security, and traffic management at the cost of considerable complexity and a mild feeling that you have lost control of your own architecture. Our first Istio deployment doubled our pod count and introduced latency that made our application feel like it was wading through treacle. Tuning it took weeks and required someone with a master’s degree in distributed systems and the patience of a saint. When it finally worked, it was magnificent. Requests flowed like water, security policies enforced themselves with silent efficiency, and I felt like a man who had tamed a tiger through sheer persistence and a lot of treats.
Cloud Deploy and the gentle art of not breaking everything
Progressive delivery sounds like something a management consultant would propose during a particularly expensive lunch, but Cloud Deploy makes it almost sensible. The service orchestrates rollouts across environments with strategies like canary and blue-green, which are named after birds and colours because naming things is hard, and DevOps engineers have a certain whimsical desperation about them.
My first successful canary deployment felt like performing surgery on a patient who was also the anaesthetist. We routed 5 percent of traffic to the new version and watched our metrics like nervous parents at a school play. When errors spiked, I expected a frantic rollback procedure involving SSH and tarballs. Instead, I clicked a button, and everything reverted in thirty seconds. The old version simply reappeared, fully formed, like a magic trick performed by someone who actually understands magic. I walked around the office for the rest of the day with what my colleagues described as a smug grin, though I prefer to think of it as the justified expression of someone who has witnessed a minor miracle.
The integration with Cloud Build creates a pipeline so smooth it is almost suspicious. Code commits trigger builds, builds trigger deployments, deployments trigger monitoring alerts, and alerts trigger automated rollbacks. It is a closed loop, a perpetual motion machine of software delivery. I once watched this entire chain execute while I was making a sandwich. By the time I had finished my ham and pickle on rye, a critical bug had been introduced, detected, and removed from production without any human intervention. I was simultaneously impressed and vaguely concerned about my own obsolescence.
Artifact Registry where containers go to mature
Storing artifacts used to involve a self-hosted Nexus repository that required weekly sacrifices of disk space and RAM. Artifact Registry is Google’s answer to this, a fully managed service that stores Docker images, Helm charts, and language packages with the solemnity of a wine cellar for code.
The vulnerability scanning here is particularly thorough, examining every layer of your container with the obsessive attention of someone who alphabetises their spice rack. It once flagged a high-severity issue in a base image we had been using for six months. The vulnerability allowed arbitrary code execution, which is the digital equivalent of leaving your front door open with a sign saying “Free laptops inside.” We had to rebuild and redeploy forty services in two days. The scanner, naturally, had known about this all along but had been politely waiting for us to notice.
Geo-replication is another feature that seems obvious until you need it. Our New Zealand team was pulling images from a European registry, which meant every deployment involved sending gigabytes of data halfway around the world. This worked about as well as shouting instructions across a rugby field during a storm. Moving to a regional registry in New Zealand cut our deployment times by half and our egress fees by a third. It also taught me that cloud networking operates on principles that are part physics, part economics, and part black magic.
Cloud Operations Suite or how I learned to love the machine that watches me
Observability in GCP is orchestrated by the Cloud Operations Suite, formerly known as Stackdriver. The rebranding was presumably because Stackdriver sounded too much like a dating app for developers, which is a missed opportunity if you ask me.
The suite unifies logs, metrics, traces, and dashboards into a single interface that is both comprehensive and bewildering. The first time I opened Cloud Monitoring, I was presented with more graphs than a hedge fund’s annual report. CPU, memory, network throughput, disk IOPS, custom metrics, uptime checks, and SLO burn rates. It was beautiful and terrifying, like watching the inner workings of a living organism that you have created but do not fully understand.
Setting up SLOs felt like writing a promise to my future self. “I, a DevOps engineer of sound mind, do hereby commit to maintaining 99.9 percent availability.” The system then watches your service like a particularly judgmental deity and alerts you the moment you transgress. I once received a burn rate alert at 2 AM because a pod had been slightly slow for ten minutes. I lay in bed, staring at my phone, wondering whether to fix it or simply accept that perfection was unattainable and go back to sleep. I fixed it, of course. We always do.
The integration with BigQuery for long-term analysis is where things get properly clever. We export all our logs and run SQL queries to find patterns. This is essentially data archaeology, sifting through digital sediment to understand why something broke three weeks ago. I discovered that our highest error rates always occurred on Tuesdays between 2 and 3 PM. Why? A scheduled job that had been deprecated but never removed, running on a server everyone had forgotten about. Finding it felt like discovering a Roman coin in your garden, exciting but also slightly embarrassing that you hadn’t noticed it before.
Cloud Monitoring and Logging the digital equivalent of a nervous system
Cloud Logging centralises petabytes of data from services that generate logs with the enthusiasm of a teenager documenting their lunch. Querying this data feels like using a search engine that actually works, which is disconcerting when you’re used to grep and prayer.
I once spent an afternoon tracking down a memory leak using Cloud Profiler, a service that shows you exactly where your code is being wasteful with RAM. It highlighted a function that was allocating memory like a government department allocates paper clips, with cheerful abandon and no regard for consequences. The function turned out to be logging entire database responses for debugging purposes, in production, for six months. We had archived more debug data than actual business data. The developer responsible, when confronted, simply shrugged and said it had seemed like a good idea at the time. This is the eternal DevOps tragedy. Everything seems like a good idea at the time.
Uptime checks are another small miracle. We have probes hitting our endpoints from locations around the world, like a global network of extremely polite bouncers constantly asking, “Are you open?” When Mumbai couldn’t reach our service but London could, it led us to discover a regional DNS issue that would have taken days to diagnose otherwise. The probes had saved us, and they had done so without complaining once, which is more than can be said for the on-call engineer who had to explain it to management at 6 AM.
Cloud Functions and Cloud Run, where code goes to hide
Serverless computing in GCP comes in two flavours. Cloud Functions are for small, event-driven scripts, like having a very eager intern who only works when you clap. Cloud Run is for containerised applications that scale to zero, which is an economical way of saying they disappear when nobody needs them and materialise when they do, like an introverted ghost.
I use Cloud Functions for automation tasks that would otherwise require cron jobs on a VM that someone has to maintain. One function resizes GKE clusters based on Cloud Monitoring alerts. When CPU utilisation exceeds 80 percent for five minutes, the function spins up additional nodes. When it drops below 20 percent, it scales down. This is brilliant until you realise you’ve created a feedback loop and the cluster is now oscillating between one node and one hundred nodes every ten minutes. Tuning the thresholds took longer than writing the function, which is the serverless way.
Cloud Run hosts our internal tools, the dashboards, and debug interfaces that developers need but nobody wants to provision infrastructure for. Deploying is gloriously simple. You push a container, it runs. The cold start time is sub-second, which means Google has solved a problem that Lambda users have been complaining about for years, presumably by bargaining with physics itself. I once deployed a debugging tool during an incident response. It was live before the engineer who requested it had finished describing what they needed. Their expression was that of someone who had asked for a coffee and been given a flying saucer.
Terraform and Cloud Deployment Manager arguing with machines about infrastructure
Infrastructure as Code is the principle that you should be able to rebuild your entire environment from a text file, which is lovely in theory and slightly terrifying in practice. Terraform, using the GCP provider, is the de facto standard. It is also a source of endless frustration and occasional joy.
The state file is the heart of the problem. It is a JSON representation of your infrastructure that Terraform keeps in Cloud Storage, and it is the single source of truth until someone deletes it by accident, at which point the truth becomes rather more philosophical. We lock the state during applies, which prevents conflicts but also means that if an apply hangs, everyone is blocked. I have spent afternoons staring at a terminal, watching Terraform ponder the nature of a load balancer, like a stoned philosophy student contemplating a spoon.
Deployment Manager is Google’s native IaC tool, which uses YAML and is therefore slightly less powerful but considerably easier to read. I use it for simple projects where Terraform would be like using a sledgehammer to crack a nut, if the sledgehammer required you to understand graph theory. The two tools coexist uneasily, like cats who tolerate each other for the sake of the humans.
Drift detection is where things get properly philosophical. Terraform tells you when reality has diverged from your code, which happens more often than you’d think. Someone clicks something in the console, a service account is modified, a firewall rule is added for “just a quick test.” The plan output shows these changes like a disappointed teacher marking homework in red pen. You can either apply the correction or accept that your infrastructure has developed a life of its own and is now making decisions independently. Sometimes I let the drift stand, just to see what happens. This is how accidents become features.
IAM and Cloud Asset Inventory, the endless game of who can do what
Identity and Access Management in GCP is both comprehensive and maddening. Every API call is authenticated and authorised, which is excellent for security but means you spend half your life granting permissions to service accounts. A service account, for the uninitiated, is a machine pretending to be a person so it can ask Google for things. They are like employees who never take a holiday but also never buy you a birthday card.
Workload Identity Federation allows these synthetic employees to impersonate each other across clouds, which is identity management crossed with method acting. We use it to let our AWS workloads access GCP resources, a process that feels rather like introducing two friends who are suspicious of each other and speak different languages. When it works, it is seamless. When it fails, the error messages are so cryptic they may as well be in Linear B.
Cloud Asset Inventory catalogs every resource in your organisation, which is invaluable for audits and deeply unsettling when you realise just how many things you’ve created and forgotten about. I once ran a report and discovered seventeen unused load balancers, three buckets full of logs from a project that ended in 2023, and a Cloud SQL instance that had been running for six months with no connections. The bill was modest, but the sense of waste was profound. I felt like a hoarder being confronted with their own clutter.
For European enterprises, the GDPR compliance features are critical. We export audit logs to BigQuery and run queries to prove data residency. The auditors, when they arrived, were suspicious of everything, which is their job. They asked for proof that data never left the europe-west3 region. I showed them VPC Service Controls, which are like digital border guards that shoot packets trying to cross geographical boundaries. They seemed satisfied, though one of them asked me to explain Kubernetes, and I saw his eyes glaze over in the first thirty seconds. Some concepts are simply too abstract for mortal minds.
Eventarc and Cloud Scheduler the nervous system of the cloud
Eventarc routes events from over 100 sources to your serverless functions, creating event-driven architectures that are both elegant and impossible to debug. An event is a notification that something happened, somewhere, and now something else should happen somewhere else. It is causality at a distance, action at a remove.
I have an Eventarc trigger that fires when a vulnerability is found, sending a message to Pub/Sub, which fans out to multiple subscribers. One subscriber posts to Slack, another creates a ticket, and a third quarantines the image. It is a beautiful, asynchronous ballet that I cannot fully trace. When it fails, it fails silently, like a mime having a heart attack. The dead-letter queue catches the casualties, which I check weekly like a coroner reviewing unexplained deaths.
Cloud Scheduler handles cron jobs, which are the digital equivalent of remembering to take the bins out. We have schedules that scale down non-production environments at night, saving money and carbon. I once set the timezone incorrectly and scaled down the production cluster at midday. The outage lasted three minutes, but the shame lasted considerably longer. The team now calls me “the scheduler whisperer,” which is not the compliment it sounds like.
The real power comes from chaining these services. A Monitoring alert triggers Eventarc, which invokes a Cloud Function, which checks something via Scheduler, which then triggers another function to remediate. It is a Rube Goldberg machine built of code, more complex than it needs to be, but weirdly satisfying when it works. I have built systems that heal themselves, which is either the pinnacle of DevOps achievement or the first step towards Skynet. I prefer to think it is the former.
The map we all pretend to understand
Every DevOps journey, no matter how anecdotal, eventually requires what consultants call a “high-level architecture overview” and what I call a desperate attempt to comprehend the incomprehensible. During my second year on GCP, I created exactly such a diagram to explain to our CFO why we were spending $47,000 a month on something called “Cross-Regional Egress.” The CFO remained unmoved, but the diagram became my Rosetta Stone for navigating the platform’s ten core services.
I’ve reproduced it here partly because I spent three entire afternoons aligning boxes in Lucidchart, and partly because even the most narrative-driven among us occasionally needs to see the forest’s edge while wandering through the trees. Consider it the technical appendix you can safely ignore, unless you’re the poor soul actually implementing any of this.
There it is, in all its tabular glory. Five rows that represent roughly fifteen thousand hours of human effort, and at least three separate incidents involving accidentally deleted production namespaces. The arrows are neat and tidy, which is more than can be said for any actual implementation.
I keep a laminated copy taped to my monitor, not because I consult it; I have the contents memorised, along with the scars that accompany each service, but because it serves as a reminder that even the most chaotic systems can be reduced to something that looks orderly on PowerPoint. The real magic lives in the gaps between those tidy boxes, where service accounts mysteriously expire, where network policies behave like quantum particles, and where the monthly bill arrives with numbers that seem generated by a random number generator with a grudge.
A modest proposal for surviving GCP
That table represents the map. What follows is the territory, with all its muddy bootprints and unexpected cliffs.
After three years, I have learned that the best DevOps engineers are not the ones with the most certificates. They are the ones who have learned to read the runes, who know which logs matter and which can be ignored, who have developed an intuitive sense for when a deployment is about to fail and can smell a misconfigured IAM binding at fifty paces. They are part sysadmin, part detective, part wizard.
The platform makes many things possible, but it does not make them easy. It is infrastructure for grown-ups, which is to say it trusts you to make expensive mistakes and learn from them. My advice is to start small, automate everything, and keep a sense of humour. You will need it the first time you accidentally delete a production bucket and discover that the undo button is marked “open a support ticket and wait.”
Store your manifests in Git and let Cloud Deploy handle the applying. Define SLOs and let the machines judge you. Tag resources for cost allocation and prepare to be horrified by the results. Replicate artifacts across regions because the internet is not as reliable as we pretend. And above all, remember that the cloud is not magic. It is simply other people’s computers running other people’s code, orchestrated by APIs that are occasionally documented and frequently misunderstood.
We build on these foundations because they let us move faster, scale further, and sleep slightly better at night, knowing that somewhere in a data centre in Belgium, a robot is watching our servers and will wake us only if things get truly interesting.
That is the theory, anyway. In practice, I still keep my phone on loud, just in case.
The Slack notification arrived with the heavy, damp enthusiasm of a wet dog jumping into your lap while you are wearing a tuxedo. It was late on a Thursday, the specific hour when ambitious caffeine consumption turns into existential regret, and the message was brief.
“I don’t think I can do this anymore. Not the coding. The infrastructure. I’m out.”
This wasn’t a junior developer overwhelmed by the concept of recursion. This was my lead backend engineer. A human Swiss Army knife who had spent nine years navigating the dark alleys of distributed systems and could stare down a production outage with the heart rate of a sleeping tortoise. He wasn’t leaving because of burnout from long hours, or an equity dispute, or even because someone microwaved fish in the breakroom.
He was leaving because of Kubernetes.
Specifically, he was leaving because the tool we had adopted to “simplify” our lives had slowly morphed into a second, unpaid job that required the patience of a saint and the forensic skills of a crime scene investigator. We had turned his daily routine of shipping features into a high-stakes game of operation where touching the wrong YAML indentation caused the digital equivalent of a sewer backup.
It was a wake-up call that hit me harder than the realization that the Tupperware at the back of my fridge has evolved its own civilization. We treat Kubernetes like a badge of honor, a maturity medal we pin to our chests. But the dirty secret everyone is too polite to whisper at conferences is that we have invited a chaotic, high-maintenance tyrant into our homes and given it the master bedroom.
When the orchestrator becomes a lifestyle disease
We tend to talk about “cognitive load” in engineering with the same sterile detachment we use to discuss disk space or latency. It sounds clean. Manageable. But in practice, the cognitive load imposed by a raw, unabstracted Kubernetes setup is less like a hard drive filling up and more like trying to cook a five-course gourmet meal while a badger is gnawing on your ankle.
The promise was seductive. We were told that Kubernetes would be the universal adapter for the cloud. It would be the operating system of the internet. And in a way, it is. But it is an operating system that requires you to assemble the kernel by hand every morning before you can open your web browser.
My star engineer didn’t want to leave. He just wanted to write code that solved business problems. Instead, he found himself spending 40% of his week debugging ingress controllers that behaved like moody teenagers (silent, sullen, and refusing to do what they were told) and wrestling with pod eviction policies that seemed based on the whim of a vengeful god rather than logic.
We had fallen into the classic trap of Resume Driven Development. We handed application developers the keys to the cluster and told them they were now “DevOps empowered.” In reality, this is like handing a teenager the keys to a nuclear submarine because they once successfully drove a golf cart. It doesn’t empower them. It terrifies them.
(And let’s be honest, most backend developers look at a Kubernetes manifest with the same mix of confusion and horror that I feel when looking at my own tax returns.)
The archaeological dig of institutional knowledge
The problem with complexity is that it rarely announces itself with a marching band. It accumulates silently, like dust bunnies under a bed, or plaque in an artery.
When we audited our setup after the resignation, we found that our cluster had become a museum of good intentions gone wrong. We found Helm charts that were so customized they effectively constituted a new, undocumented programming language. We found sidecar containers attached to pods for reasons nobody could remember, sucking up resources like barnacles on the hull of a ship, serving no purpose other than to make the diagrams look impressive.
This is what I call “Institutional Knowledge Debt.” It represents the sort of fungal growth that occurs when you let complexity run wild. You know it is there, evolving its own ecosystem, but as long as you don’t look at it directly, you don’t have to acknowledge that it might be sentient.
The “Bus Factor” in our team (the number of people who can get hit by a bus before the project collapses) had reached a terrifying number: one. And that one person had just quit. We had built a system where deploying a hotfix required a level of tribal knowledge usually reserved for initiating members into a secret society.
YAML is just a ransom note with better indentation
If you want to understand why developers hate modern infrastructure, look no further than the file format we use to define it. YAML.
We found files in our repository that were less like configuration instructions and more like love letters written by a stalker: intense, repetitive, and terrifyingly vague about their actual intentions.
The fragility of it is almost impressive. A single misplaced space, a tab character where a space should be, or a dash that looked at you the wrong way, and the entire production environment simply decides to take the day off. It is absurd that in an era of AI assistants and quantum computing, our billion-dollar industries hinge on whether a human being pressed the spacebar two times or four times.
Debugging these files is not engineering. It is hermeneutics. It is reading tea leaves. You stare at the CrashLoopBackOff error message, which is the system’s way of saying “I am unhappy, but I will not tell you why,” and you start making sacrifices to the gods of indentation.
My engineer didn’t hate the logic. He hated the medium. He hated that his intellect was being wasted on the digital equivalent of untangling Christmas lights.
We built a platform to stop the bleeding
The solution to this mess was not to hire “better” engineers who memorized the entire Kubernetes API documentation. That is a strategy akin to buying larger pants instead of going on a diet. It accommodates the problem, but it doesn’t solve it.
We had to perform an exorcism. But not a dramatic one with spinning heads. A boring, bureaucratic one.
We embraced Platform Engineering. Now, that is a buzzword that usually makes my eyes roll back into my head so far I can see my own frontal lobe, but in this case, it was the only way out. We decided to treat the platform as a product and our developers as the customers, customers who are easily confused and frighten easily.
We took the sharp objects away.
We built “Golden Paths.” In plain English, this means we created templates that work. If a developer wants to deploy a microservice, they don’t need to write a 400-line YAML manifesto. They fill out a form that asks five questions: What is it called? How much memory does it need? Who do we call if it breaks?
We hid the Kubernetes API behind a curtain. We stopped asking application developers to care about PodDisruptionBudgets or AffinityRules. Asking a Java developer to configure node affinity is like asking a passenger on an airplane to help calibrate the landing gear. It is not their job, and if they are doing it, something has gone terribly wrong.
Boring is the only metric that matters
After three months of stripping away the complexity, something strange happened. The silence.
The Slack channel dedicated to deployment support, previously a scrolling wall of panic and “why is my pod pending?” screenshots, went quiet. Deployments became boring.
And let me tell you, in the world of infrastructure, boring is the new sexy. Boring means things work. Boring means I can sleep through the night without my phone buzzing across the nightstand like an angry hornet.
Kubernetes is a marvel of engineering. It is powerful, scalable, and robust. But it is also a dense, hostile environment for humans. It is an industrial-grade tool. You don’t put an industrial lathe in your home kitchen to slice carrots, and you shouldn’t force every developer to operate a raw Kubernetes cluster just to serve a web page.
If you are hiring brilliant engineers, you are paying for their ability to solve logic puzzles and build features. If you force them to spend half their week fighting with infrastructure, you are effectively paying a surgeon to mop the hospital floors.
So look at your team. Look at their eyes. If they look tired, not from the joy of creation but from the fatigue of fighting their own tools, you might have a problem. That star engineer isn’t planning their next feature. They are drafting their resignation letter, and it probably won’t be written in YAML.
I have a theory that usually gets me uninvited to the best tech parties. It is a controversial opinion, the kind that makes people shift uncomfortably in their ergonomic chairs and check their phones. Here it is. AWS is not expensive. AWS is actually a remarkably fair judge of character. Most of us are just bad at using it. We are not unlucky, nor are we victims of some grand conspiracy by Jeff Bezos to empty our bank accounts. We are simply lazy in ways that we are too embarrassed to admit.
I learned this the hard way, through a process that felt less like a financial audit and more like a very public intervention.
The expensive silence of a six-figure mistake
Last year, our AWS bill crossed a number that made the people in finance visibly sweat. It was a six-figure sum appearing monthly, a recurring nightmare dressed up as an invoice. The immediate reactions from the team were predictable: a chorus of denial that sounded like a broken record. People started whispering about the insanity of cloud pricing. We talked about negotiating discounts, even though we had no leverage. There was serious talk of going multi-cloud, which is usually just a way to double your problems while hoping for a synergy that never comes. Someone even suggested going back to on-prem servers, which is the technological equivalent of moving back in with your parents because your rent is too high.
We were looking for a villain, but the only villain in the room was our own negligence. Instead of pointing fingers at Amazon, we froze all new infrastructure for two weeks. We locked the doors and audited why every single dollar existed. It was painful. It was awkward. It was necessary.
We hired a therapist for our infrastructure
What we found was not a technical failure. It was a behavioral disorder. We found that AWS was not charging us for scale. It was charging us for our profound indifference. It was like leaving the water running in every sink in the house and then blaming the utility company for the price of water.
We had EC2 instances sized “just to be safe.” This is the engineering equivalent of buying a pair of XXXL sweatpants just in case you decide to take up sumo wrestling next Tuesday. We were paying for capacity we did not need, for a traffic spike that existed only in our anxious imaginations.
We discovered Kubernetes clusters wheezing along at 15% utilization. Imagine buying a Ferrari to drive to the mailbox at the end of the driveway once a week. That was our cluster. Expensive, powerful, and utterly bored.
There were NAT Gateways chugging along in the background, charging us by the gigabyte to forward traffic that nobody remembered creating. It was like paying a toll to cross a bridge that went nowhere. We had RDS instances over-provisioned for traffic that never arrived, like a restaurant staffed with fifty waiters for a lunch crowd of three.
Perhaps the most revealing discovery was our log retention policy. We were keeping CloudWatch logs forever because “storage is cheap.” It is not cheap when you are hoarding digital exhaust like a cat lady hoarding newspapers. We had autoscaling enabled without upper bounds, which is a bit like giving your credit card to a teenager and telling them to have fun. We had Lambdas retrying silently into infinity, little workers banging their heads against a wall forever.
None of this was AWS being greedy. This was engineering apathy. This was the result of a comforting myth that engineers love to tell themselves.
The hoarding habit of the modern engineer
“If it works, do not touch it.”
This mantra makes sense for stability. It is a lovely sentiment for a grandmother’s antique clock. It is a disaster for a cloud budget. AWS does not reward working systems. It rewards intentional systems. Every unmanaged default becomes a subscription you never canceled, a gym membership you keep paying for because you are too lazy to pick up the phone and cancel it.
Big companies can survive this kind of bad cloud usage because they can hide the waste in the couch cushions of their massive budgets. Startups cannot. For a startup, a few bad decisions can double your runway burn, force hiring freezes, and kill experimentation before it begins. I have seen companies rip out AWS, not because the technology failed, but because they never learned how to say no to it. They treated the cloud like an all you can eat buffet, where they forgot to pay the bill first.
Denial is a terrible financial strategy
If your AWS bill feels random, you do not understand your system. If cost surprises you, your architecture is opaque. It is like finding a surprise charge on your credit card and realizing you have no idea what you bought. It is a loss of control.
We realized that if we needed a “FinOps tool” to explain our bill, our infrastructure was already too complex. We did not need another dashboard. We needed a mirror.
The boring magic of actually caring
We did not switch clouds. We did not hire expensive consultants to tell us what we already knew. We did not buy magic software to fix our mess. We did four boring, profoundly unsexy things.
First, every resource needed an owner. We stopped treating servers like communal property. If you spun it up, you fed it. Second, every service needed a cost ceiling. We put a leash on the spending. Third, every autoscaler needed a maximum limit. We stopped the machines from reproducing without permission. Fourth, every log needed a delete date. We learned to take out the trash.
The results were almost insulting in their simplicity. Costs dropped 43% in 30 days. There were no outages. There were no late night heroics. We did not rewrite the core platform. We just applied a little bit of discipline.
Why this makes engineers uncomfortable
Cost optimization exposes bad decisions. It forces you to admit that you over engineered a solution. It forces you to admit that you scaled too early. It forces you to admit that you trusted defaults because you were too busy to read the manual. It forces you to admit that you avoided the hard conversations about budget.
It is much easier to blame AWS. It is comforting to think of them as a villain. It is harder to admit that we built something nobody questioned.
The brutal honesty of the invoice
AWS is not the villain here. It is a mirror. It shows you exactly how careless or thoughtful your architecture is, and it translates that carelessness into dollars. You can call it expensive. You can call it unfair. You can migrate to another cloud provider. But until you fix how you design systems, every cloud will punish you the same way. The problem is not the landlord. The problem is how you are living in the house.
It brings me to a final question that every engineering leader should ask themselves. If your AWS bill doubled tomorrow, would you know why? Would you know exactly where the money was going? Would you know what to delete first?
If the answer is no, the problem is not AWS. And deep down, in the quiet moments when the invoice arrives, you already know that. This article might make some people angry. That is good. Anger is cheaper than denial. And frankly, it is much better for your bottom line.
Someone in a zip-up hoodie has just told you that monoliths are architectural heresy. They insist that proper companies, the grown-up ones with rooftop terraces and kombucha taps in the breakroom, build systems the way squirrels store acorns. They describe hundreds of tiny, frantic caches scattered across the forest floor, each with its own API, its own database, and its own emotional baggage.
You stand there nodding along while holding your warm beer, feeling vaguely inadequate. You hide the shameful secret that your application compiles in less time than it takes to brew a coffee. You do not mention that your code lives in a repository that does not require a map and a compass to navigate. Your system runs on something scandalously simple. It is a monolith.
Welcome to the cult of small things. We have been expecting you, and we have prepared a very complicated seat for you.
The insecurity of the monolithic developer
The microservices revolution did not begin with logic. It began with envy. It started with a handful of very successful case studies that functioned less like technical blueprints and more like impossible beauty standards for teenagers.
Netflix streams billions of hours of video. Amazon ships everything from electric toothbrushes to tactical uranium (probably) to your door in two days. Their systems are vast, distributed, and miraculous. So the industry did what any rational group of humans would do. We copied their homework without checking if we were taking the same class.
We looked at Amazon’s architecture and decided that our internal employee timesheet application needed the same level of distributed complexity as a global logistics network. This is like buying a Formula 1 pit crew to help you parallel park a Honda Civic. It is technically impressive, sure. But it is also a cry for help.
Suddenly, admitting you maintained a monolith became a confession. Teams began introducing themselves at conferences by stating their number of microservices, the way bodybuilders flex biceps, or suburban dads compare lawn mower horsepower. “We are at 150 microservices,” someone would say, and the crowd would murmur approval. Nobody thought to ask if those services did anything useful. Nobody questioned whether the team spent more time debugging network calls than writing features.
The promise was flexibility. The reality became a different kind of rigidity. We traded the “spaghetti code” of the monolith for something far worse. We built a distributed bowl of spaghetti where the meatballs are hosted on different continents, and the sauce requires a security token to touch the pasta.
Debugging a murder mystery where the body keeps moving
Here is what the brochures and the medium articles do not mention. Debugging a monolith is straightforward. You follow the stack trace like a detective following footprints in the snow.
Debugging a distributed system, however, is less like solving a murder mystery and more like investigating a haunting. The evidence vanishes. The logs are in different time zones. Requests pass through so many services that by the time you find the culprit, you have forgotten the crime.
Everything works perfectly in isolation. This is the great lie of the unit test. Your service A works fine. Your service B works fine. But when you put them together, you get a Rube Goldberg machine that occasionally processes invoices but mostly generates heat and confusion.
To solve this, we invented “observability,” which is a fancy word for hiring a digital private investigator to stalk your own code. You need a service discovery tool. Then, a distributed tracing library. Then a circuit breaker, a bulkhead, a sidecar proxy, a configuration server, and a small shrine to the gods of eventual consistency.
Your developer productivity begins a gentle, heartbreaking decline. A simple feature, such as adding a “middle name” field to a user profile, now requires coordinating three teams, two API version bumps, and a change management ticket that will be reviewed next Thursday. The context switching alone shaves IQ points off your day. You have solved the complexity of the monolith by creating fifty mini monoliths, each with its own deployment pipeline and its own lonely maintainer who has started talking to the linter.
Your infrastructure bill is now a novelty item
There is a financial aspect to this midlife crisis. In the old days, you rented a server. Maybe two. You paid a fixed amount, and the server did the work.
In the microservices era, you are not just paying for the work. You are paying for the coordination of the work. You are paying for the network traffic between the services. You are paying for the serialization and deserialization of data that never leaves your data center. You are paying for the CPU cycles required to run the orchestration tools that manage the containers that hold the services that do the work.
It is an administrative tax. It is like hiring a construction crew where one guy hammers the nail, and twelve other guys stand around with clipboards coordinating the hammering angle, the hammer velocity, and the nail impact assessment strategy.
Amazon Prime Video found this out the hard way. In a move that shocked the industry, they published a case study detailing how they moved from a distributed, serverless architecture back to a monolithic structure for one of their core monitoring services.
The results were not subtle. They reduced their infrastructure costs by 90 percent. That is not a rounding error. That is enough money to buy a private island. Or at least a very nice yacht. They realized that sending video frames back and forth between serverless functions was the digital equivalent of mailing a singular sock to yourself one at a time. It was inefficient, expensive, and silly.
The myth of infinite scalability
Let us talk about that word. Scalability. It gets whispered in architectural reviews like a magic spell. “But will it scale?” someone asks, and suddenly you are drawing boxes and arrows on a whiteboard, each box a little fiefdom with its own database and existential dread.
Here is a secret that might get you kicked out of the hipster coffee shop. Most systems never see the traffic that justifies this complexity. Your boutique e-commerce site for artisanal cat toys does not need to handle Black Friday traffic every Tuesday. It could likely run on a well-provisioned server and a prayer. Using microservices for these workloads is like renting an aircraft hangar to store a bicycle.
Scalability comes in many flavors. You can scale a monolith horizontally behind a load balancer. You can scale specific heavy functions without splitting your entire domain model into atomic particles. Docker and containers gave us consistent deployment environments without requiring a service mesh so complex that it needs its own PhD program to operate.
The infinite scalability argument assumes you will be the next Google. Statistically, you will not. And even if you are, you can refactor later. It is much easier to slice up a monolith than it is to glue together a shattered vase.
Making peace with the boring choice
So what is the alternative? Must we return to the bad old days of unmaintainable codeballs?
No. The alternative is the modular monolith. This sounds like an oxymoron, but it functions like a dream. It is the architectural equivalent of a sensible sedan. It is not flashy. It will not make people jealous at traffic lights. But it starts every morning, it carries all your groceries, and it does not require a specialized mechanic flown in from Italy to change the oil.
You separate concerns inside the same codebase. You make your boundaries clear. You enforce modularity with code structure rather than network latency. When a module truly needs to scale differently, or a team truly needs autonomy, you extract it. You do this not because a conference speaker told you to, but because your profiler and your sprint retrospectives are screaming it.
Your architecture should match your team size. Three engineers do not need a service per person. They need a codebase they can understand without opening seventeen browser tabs. There is no shame in this. The shame is in building a distributed system so brittle that every deploy feels like defusing a bomb in an action movie, but without the cool soundtrack.
Epilogue
Architectural patterns are like diet fads. They come in waves, each promising total transformation. One decade, it is all about small meals, the next it is intermittent fasting, the next it is eating only raw meat like a caveman.
The truth is boring and unmarketable. Balance works. Microservices have their place. They are essential for organizations with thousands of developers who need to work in parallel without stepping on each other’s toes. They are great for systems that genuinely have distinct, isolated scaling needs.
For everything else, simplicity remains the ultimate sophistication. It is also the ultimate sanity preserver.
Next time someone tells you monoliths are dead, ask them how many incident response meetings they attended this week. The answer might be all the architecture review you need.
(Footnote: If they answer “zero,” they are either lying, or their pager duty alerts are currently stuck in a dead letter queue somewhere between Service A and Service B.)
If you looked inside a running Kubernetes cluster with a microscope, you would not see a perfectly choreographed ballet of binary code. You would see a frantic, crowded open-plan office staffed by thousands of employees who have consumed dangerous amounts of espresso. You have schedulers, controllers, and kubelets all sprinting around, frantically trying to update databases and move containers without crashing into each other.
It is a miracle that the whole thing does not collapse into a pile of digital rubble within seconds. Most human organizations of this size descend into bureaucratic infighting before lunch. Yet, somehow, Kubernetes keeps this digital circus from turning into a riot.
You might assume that the mechanism preventing this chaos is a highly sophisticated, cryptographic algorithm forged in the fires of advanced mathematics. It is not. The thing that keeps your cluster from eating itself is the distributed systems equivalent of a sticky note on a door. It is called a Lease.
And without this primitive, slightly passive-aggressive little object, your entire cloud infrastructure would descend into anarchy faster than you can type kubectl delete namespace.
The sticky note of power
To understand why a Lease is necessary, we have to look at the psychology of a Kubernetes controller. These components are, by design, incredibly anxious. They want to ensure that the desired state of the world matches the actual state.
The problem arises when you want high availability. You cannot just have one controller running because if it dies, your cluster stops working. So you run three replicas. But now you have a new problem. If all three replicas try to update the same routing table or create the same pod at the exact same moment, you get a “split-brain” scenario. This is the technical term for a psychiatric emergency where the left hand deletes what the right hand just created.
Kubernetes solves this with the Lease object. Technically, it is an API resource in the coordination.k8s.io group. Spiritually, it is a “Do Not Disturb” sign hung on a doorknob.
If you look at the YAML definition of a Lease, it is almost insultingly simple. It does not ask for a security clearance or a biometric scan. It essentially asks three questions:
HolderIdentity: Who are you?
LeaseDurationSeconds: How long are you going to be in there?
RenewTime: When was the last time you shouted that you are still alive?
In plain English, this document says: “Controller Beta-09 is holding the steering wheel. It has fifteen seconds to prove it has not died of a heart attack. If it stays silent for sixteen seconds, we are legally allowed to pry the wheel from its cold, dead fingers.”
An awkward social experiment
To really grasp the beauty of this system, we need to leave the server room and enter a shared apartment with a terrible design flaw. There is only one bathroom, the lock is broken, and there are five roommates who all drank too much water.
The bathroom is the “critical resource.” In a computerized world without Leases, everyone would just barge in whenever they felt the urge. This leads to what engineers call a “race condition” and what normal people call “an extremely embarrassing encounter.”
Since we cannot fix the lock, we install a whiteboard on the door. This is the Lease.
The rules of this apartment are strict but effective. When you walk up to the door, you write your name and the current time on the board. You have now acquired the lock. As long as your name is there and the timestamp is fresh, the other roommates will stand in the hallway, crossing their legs and waiting politely.
But here is where it gets stressful. You cannot just write your name and fall asleep in the tub. The system requires constant anxiety. Every few seconds, you have to crack the door open, reach out with a marker, and update the timestamp. This is the “heartbeat.” It tells the people waiting outside that you are still conscious and haven’t slipped in the shower.
If you faint, or if the WiFi cuts out and you cannot reach the whiteboard, you stop updating the time. The roommates outside watch the clock. Ten seconds pass. Fifteen seconds. At sixteen seconds, they do not knock to see if you are okay. They assume you are gone forever, wipe your name off the board, write their own, and barge in.
It is ruthless, but it ensures that the bathroom is never left empty just because the previous occupant vanished into the void.
The paranoia of leader election
The most critical use of this bathroom logic is something called Leader Election. This is the mechanism that keeps your kube-controller-manager and kube scheduler from turning into a bar fight.
You typically run multiple copies of these control plane components for redundancy. However, you absolutely cannot have five different schedulers trying to assign the same pod to five different nodes simultaneously. That would be like having five conductors trying to lead the same orchestra. You do not get music; you get noise and a lot of angry musicians.
So, the replicas hold an election. But it is not a democratic vote with speeches and ballots. It is a race to grab the marker.
The moment the controllers start up, they all rush toward the Lease object. The first one to write its name in the holderIdentity field becomes the Leader. The others, the candidates, do not go home. They stand in the corner, staring at the Lease, refreshing the page every two seconds, waiting for the Leader to fail.
There is something deeply human about this setup. The backup replicas are not “supporting” the leader. They are jealous understudies watching the lead actor, hoping he breaks a leg so they can take center stage.
If the Leader crashes or simply gets stuck in a network traffic jam, the renewTime stops updating. The lease expires. Immediately, the backups scramble to write their own name. The winner takes over the cluster duties instantly. It is seamless, automated, and driven entirely by the assumption that everyone else is unreliable.
Reducing the noise pollution
In the early days of Kubernetes, things were even messier. Nodes, the servers doing the actual work, had to prove they were alive by sending a massive status report to the API server every few seconds.
Imagine a receptionist who has to process a ten-page medical history form from every single employee every ten seconds, just to confirm they are at their desks. It was exhausting. The API server spent so much time reading these reports that it barely had time to do anything else.
Today, Kubernetes uses Leases for node heartbeats, too. Instead of the full medical report, the node just updates a Lease object. It is a quick, lightweight ping.
“I’m here.”
“Good.”
“Still here.”
“Great.”
This change reduced the computational cost of staying alive significantly. The API server no longer needs to know your blood pressure and cholesterol levels every ten seconds; it just needs to know you are breathing. It turns a bureaucratic nightmare into a simple check-in.
How to play with fire
The beauty of the Lease system is that it is just a standard Kubernetes object. You can see these invisible sticky notes right now. If you list the leases in the system namespace, you will see the invisible machinery that keeps the lights on:
kubectl get leases -n kube-system
You will see entries for the controller manager, the scheduler, and probably one for every node in your cluster. If you want to see who the current boss is, you can describe the lease:
Please do not do this in production unless you enjoy panic attacks.
Deleting an active Lease is like ripping the “Occupied” sign off the bathroom door while someone is inside. You are effectively lying to the system. You are telling the backup controllers, “The leader is dead! Long live the new leader!”
The backups will rush in and elect a new leader. But the old leader, who was effectively just sitting there minding its own business, is still running. Suddenly, it realizes it has been fired without notice. Ideally, it steps down gracefully. But in the split second before it realizes what happened, you might have two controllers giving orders.
The system will heal itself, usually within seconds, but those few seconds are a period of profound confusion for everyone involved.
The survival of the loudest
Leases are the unsung heroes of the cloud native world. We like to talk about Service Meshes and eBPF and other shiny, complex technologies. But at the bottom of the stack, keeping the whole thing from exploding, is a mechanism as simple as a name on a whiteboard.
It works because it accepts a fundamental truth about distributed systems: nothing is reliable, everyone is going to crash eventually, and the only way to maintain order is to force components to shout “I am alive!” every few seconds.
Next time your cluster survives a node failure or a controller restart without you even noticing, spare a thought for the humble Lease. It is out there in the void, frantically renewing timestamps, protecting you from the chaos of a split-brain scenario. And that is frankly better than a lock on a bathroom door any day.
Thursday, 3:47 AM. Your server is named Nigel. You named him Nigel because deep down, despite the silicon and the circuitry, he feels like a man who organizes his spice rack alphabetically by the Latin name of the plant. But right now, Nigel is not organizing spices. Nigel has decided to stage a full-blown existential rebellion.
The screen is black. The network fan is humming with a tone of passive-aggressive silence. A cursor blinks in the upper-left corner with a rhythm that seems designed specifically to induce migraines. You reboot. Nigel reboots. Nothing changes. The machine is technically “on,” in the same way a teenager staring at the ceiling for six hours is technically “awake.”
At this moment, the question separating the seasoned DevOps engineer from the panicked googler is not “Why me?” but rather: Which personality did Nigel wake up with today?
This is not a technical question. It is a psychological one. Linux does not break at random; it merely changes moods. It has emotional states. And once you learn to read them, troubleshooting becomes less like exorcising a demon and more like coaxing a sulking relative out of the bathroom during Thanksgiving dinner.
The grumpy grandfather who started it all
We lived in a numeric purgatory for years. In an era when “multitasking” sounded like dangerous witchcraft and coffee came only in one flavor (scorched), Linux used a system called SysVinit to manage its temperaments. This system boiled the entire machine’s existence down to a handful of numbers, zero through six, called runlevels.
It was a rigid caste system. Each number was a dial you could turn to decide how much Nigel was willing to participate in society.
Runlevel 0 meant Nigel was checking out completely. Death. Runlevel 6 meant Nigel had decided to reincarnate. Runlevel 1 was Nigel as a hermit monk, holed up in a cave with no network, no friends, just a single shell and a vow of digital silence. Runlevel 5 was Nigel on espresso and antidepressants, graphical interface blazing, ready to party and consume RAM for no apparent reason.
This was functional, in the way a Soviet-era tractor is functional. It was also about as intuitive as a dishwasher manual written in cuneiform. You would tell a junior admin to “boot to runlevel 3,” and they would nod while internally screaming. What does three mean? Is it better than two? Is five twice as good as three? The numbers did not describe anything; they just were, like the arbitrary rules of a board game invented by someone who actively hated you.
And then there was runlevel 4. Runlevel 4 is the appendix of the Linux anatomy. It is vaguely present, historically relevant, but currently just taking up space. It was the “user-definable” switch in your childhood home that either did nothing or controlled the neighbor’s garage door. It sits there, unused, gathering digital dust.
Enter the overly organized therapist
Then came systemd. If SysVinit was a grumpy grandfather, systemd is the high-energy hospital administrator who carries a clipboard and yells at people for walking too slowly. Systemd took one look at those numbered mood dials and was appalled. “Numbers? Seriously? Even my router has a name.”
It replaced the cold digits with actual descriptive words: multi-user.target, graphical.target, rescue.target. It was as if Linux had finally gone to therapy and learned to use its words to express its feelings instead of grunting “runlevel 3” when it really meant “I need personal space, but WiFi would be nice.”
Targets are just runlevels with a humanities degree. They perform the exact same job, defining which services start, whether the GUI is invited to the party, whether networking gets a plus-one, but they do so with the kind of clarity that makes you wonder how we survived the numeric era without setting more server rooms on fire.
A Rosetta Stone for Nigel’s mood swings
Here is the translation guide that your cheat sheet wishes it had. Think of this as the DSM-5 for your server.
Runlevel 0 becomes poweroff.target Nigel is taking a permanent nap. This is the Irish Goodbye of operating states.
Runlevel 1 becomes rescue.target Nigel is in intensive care. Only family is allowed to visit (root user). The network is unplugged, the drives might be mounted read-only, and the atmosphere is grim. This is where you go when you have broken something fundamental and need to perform digital surgery.
Runlevel 3 becomes multi-user.target Nigel is wearing sweatpants but answering emails. This is the gold standard for servers. Networking is up, multiple users can log in, cron jobs are running, but there is no graphical interface to distract anyone. It is a state of pure, joyless productivity.
Runlevel 5 becomes graphical.target Nigel is in full business casual with a screensaver. He has loaded the window manager, the display server, and probably a wallpaper of a cat. He is ready to interact with a mouse. He is also consuming an extra gigabyte of memory just to render window shadows.
Runlevel 6 becomes reboot.target Nigel is hitting the reset button on his life.
The command line couch
Knowing Nigel’s mood is useless unless you can change it. You need tools to intervene. These are the therapy techniques you keep in your utility belt.
To eyeball Nigel’s default personality (the one he wakes up with every morning), you ask:
systemctl get-default
This might spit back graphical.target. This means Nigel is a morning person who greets the world with a smile and a heavy user interface. If it says multi-user.target, Nigel is the coffee-before-conversation type.
But sometimes, you need to force a mood change. Let’s say you want to switch Nigel from party mode (graphical) to hermit mode (text-only) without making it permanent. You are essentially putting an extrovert in a quiet room for a breather.
systemctl isolate multi-user.target
The word “isolate” here is perfect. It is not “disable” or “kill.” It is “isolate”. It sounds less like computer administration and more like what happens to the protagonist in the third act of a horror movie involving Antarctic research stations. It tells systemd to stop everything that doesn’t belong in the new target. The GUI vanishes. The silence returns.
To switch back, because sometimes you actually need the pretty buttons:
systemctl isolate graphical.target
And to permanently change Nigel’s baseline disposition, akin to telling a chronically late friend that dinner is at 6:30 when it is really at 7:00:
systemctl set-default multi-user.target
Now Nigel will always wake up in Command Line Interface mode, even after a reboot. You can practically hear the sigh of relief from your CPU as it realizes it no longer has to render pixels.
When Nigel has a real breakdown
Let’s walk through some actual disasters, because theory is just a hobby until production goes down and your boss starts hovering behind your chair breathing through his mouth.
Scenario one: The fugue state
Nigel updated his kernel and now boots to a black screen. He is not dead; he is just confused. You reboot, interrupt the boot loader, and add systemd.unit=rescue.target to the boot parameters.
Nigel wakes up in a safe room. It is a root shell. There is no networking. There is no drama. It is just you and the config files. It is intimate, in a disturbing way. You fix the offending setting, type exec /sbin/init, and Nigel reboots into his normal self, slightly embarrassed about the whole episode.
Scenario two: The toddler on espresso
Nigel’s graphical interface has started crashing like a toddler after too much sugar. Every time you log in, the desktop environment panics and dies. Instead of fighting it, you switch to multi-user.target.
Nigel is now a happy, stable server with no interest in pretty icons. Your users can still SSH in. Your automated jobs still run. Nigel just doesn’t have to perform anymore. It is like taking the toddler out of the Chuck E. Cheese and putting him in a library. The screaming stops immediately.
Scenario three: The bloatware incident
Nigel is a production web server that has inexplicably slowed to a crawl. You dig through the logs and discover that an intern (let’s call him “Not-Fernando”) installed a full desktop environment six months ago because they liked the screensaver.
This is akin to buying a Ferrari to deliver pizza because you like the leather seats. The graphical target is eating resources that your database desperately needs. You set the default to multi-user.target and reboot. Nigel comes back lean, mean, and suddenly has five hundred extra megabytes of RAM to play with. It is like watching someone shed a winter coat in the middle of July.
The mindset shift
Beginners see a black screen and ask, “Why is Nigel broken?” Professionals see a black screen and ask, “Which target is Nigel in, and which services are active?”
This is not just semantics. It is the difference between treating a symptom and diagnosing a disease. When you understand that Linux doesn’t break so much as it changes states, you stop being a victim of circumstance and start being a negotiator. You are not praying to the machine gods; you are simply asking Nigel, “Hey buddy, what mood are you in?” and then coaxing him toward a more productive state.
The panic evaporates because you know the vocabulary. You know that rescue.target is a panic room, multi-user.target is a focused work session, and graphical.target is Nigel trying to impress someone at a party.
Linux targets are not arcane theory reserved for greybeards and certification exams. They are the foundational language of state management. They are how you tell Nigel, “It is okay to be a hermit today,” or “Time to socialize,” or “Let’s check you into therapy real quick.”
Once you internalize this, boot issues stop being terrifying mysteries. They become logical puzzles. Interviews stop being interrogations. They become conversations. You stop sounding like a generic admin reading a forum post and start sounding like someone who knows Nigel personally.
Because you do. Nigel is that fussy, brilliant, occasionally melodramatic friend who just needs the right kind of encouragement. And now you have the exact words to provide it.
Docker used to be the answer you gave when someone asked, “How do we ship this thing?” Now it’s more often the answer to a different question, “How do I run this thing locally without turning my laptop into a science fair project?”
That shift is not a tragedy. It’s not even a breakup. It’s more like Docker moved out of the busy downtown apartment called “production” and into a cozy suburb called “developer experience”, where the lawns are tidy, the tools are friendly, and nobody panics if you restart everything three times before lunch.
This article is about what changed, why it changed, and why Docker is still very much worth knowing, even if your production clusters rarely whisper its name anymore.
What we mean when we say Docker
One reason this topic gets messy is that “Docker” is a single word used to describe several different things, and those things have very different jobs.
Docker Desktop is the product that many developers actually interact with day to day, especially on macOS and Windows.
Docker Engine and the Docker daemon are the background machinery that runs containers on a host.
The Docker CLI and Dockerfile workflow are the human-friendly interface and the packaging format that people have built habits around.
When someone says “Docker is dying,” they usually mean “Docker Engine is no longer the default runtime in production platforms.” When someone says “Docker is everywhere,” they often mean “Docker Desktop and Dockerfile workflows are still the easiest way to get a containerized dev environment running quickly.”
Both statements can be true at the same time, which is annoying, because humans prefer their opinions to come in single-serving packages.
Docker’s rise and the good kind of magic
Docker didn’t become popular because it invented containers. Containers existed before Docker. Docker became popular because it made containers feel approachable.
It offered a developer experience that felt like a small miracle:
You could build images with a straightforward command.
You could run containers without a small dissertation on Linux namespaces.
You could push to registries and share a runnable artifact.
You could spin up multi-service environments with Docker Compose.
Docker took something that used to feel like “advanced systems programming” and turned it into “a thing you can demo on a Tuesday.”
If you were around for the era of XAMPP, WAMP, and “download this zip file, then pray,” Docker felt like a modern version of that, except it didn’t break as soon as you looked at it funny.
The plot twist in production
Here is the part where the story becomes less romantic.
Production infrastructure grew up.
Not emotionally, obviously. Infrastructure does not have feelings. It has outages. But it did mature in a very specific way: platforms started to standardize around container runtimes and interfaces that did not require Docker’s full bundled experience.
Docker was the friendly all-in-one kitchen appliance. Production systems wanted an industrial kitchen with separate appliances, separate controls, and fewer surprises.
Three forces accelerated the shift.
Licensing concerns changed the mood
Docker Desktop licensing changes made a lot of companies pause, not because engineers suddenly hated Docker, but because legal teams developed a new hobby.
The typical sequence went like this:
Someone in finance asked, “How many Docker Desktop users do we have?”
Someone in legal asked, “What exactly are we paying for?”
Someone in infrastructure said, “We can probably do this with Podman or nerdctl.”
A tool can survive engineers complaining about it. Engineers complain about everything. The real danger is when procurement turns your favorite tool into a spreadsheet with a red cell.
The result was predictable: even developers who loved Docker started exploring alternatives, if only to reduce risk and friction.
The runtime world standardized without Docker
Modern container platforms increasingly rely on runtimes like containerd and interfaces like the Container Runtime Interface (CRI).
Kubernetes is a key example. Kubernetes removed the direct Docker integration path that many people depended on in earlier years, and the ecosystem moved toward CRI-native runtimes. The point was not to “ban Docker.” The point was to standardize around an interface designed specifically for orchestrators.
This is a subtle but important difference.
Docker is a complete experience, build, run, network, UX, opinions included.
Orchestrators prefer modular components, and they want to speak to a runtime through a stable interface.
The practical effect is what most teams feel today:
In many Kubernetes environments, the runtime is containerd, not Docker Engine.
Managed platforms such as ECS Fargate and other orchestrated services often run containers without involving Docker at all.
Docker, the daemon, became optional.
Security teams like control, and they do not like surprises
Security teams do not wake up in the morning and ask, “How can I ruin a developer’s day?” They wake up and ask, “How can I make sure the host does not become a piñata full of root access?”
Docker can be perfectly secure when used well. The problem is that it can also be spectacularly insecure when used casually.
Two recurring issues show up in real organizations:
The Docker socket is powerful. Expose it carelessly, and you are effectively offering a fast lane to host-level control.
The classic pattern of “just give developers sudo docker” can become a horror story with a polite ticket number.
Tools and workflows that separate concerns tend to make security people calmer.
Build tools such as BuildKit and buildah isolate image creation.
Rootless approaches, where feasible, reduce blast radius.
Runtime components can be locked down and audited more granularly.
This is not about blaming Docker. It’s about organizations preferring a setup where the sharp knives are stored in a drawer, not taped to the ceiling.
What Docker is now
Docker’s new role is less “the thing that runs production” and more “the thing that makes local development less painful.”
And that role is huge.
Docker still shines in areas where convenience matters most:
Local development environments
Quick reproducible demos
Multi-service stacks on a laptop
Cross-platform consistency on macOS, Windows, and Linux
Teams that need a simple standard for “how do I run this?”
If your job is to onboard new engineers quickly, Docker is still one of the best ways to avoid the dreaded onboarding ritual where a senior engineer says, “It works on my machine,” and the junior engineer quietly wonders if their machine has offended someone.
A small example that still earns its keep
Here is a minimal Docker Compose stack that demonstrates why Docker remains lovable for local development.
You can read this as “Dockerfile lives on, but Docker-as-a-daemon is no longer the main character.”
This separation matters because it changes how you design CI.
You can build images in environments where running a privileged Docker daemon is undesirable.
You can use builders that integrate better with Kubernetes or cloud-native pipelines.
You can reduce the amount of host-level power you hand out just to produce an artifact.
What replaced Docker in production pipelines
When teams say they are moving away from Docker in production, they rarely mean “we stopped using containers.” They mean the tooling around building and running containers is shifting.
Common patterns include:
containerd as the runtime in Kubernetes and other orchestrated environments
BuildKit for efficient builds and caching
kaniko for building images inside Kubernetes without a Docker daemon
ko for building and publishing Go applications as images without a Dockerfile
Buildpacks or Nixpacks for turning source code into runnable images using standardized build logic
Dagger and similar tools for defining CI pipelines that treat builds as portable graphs of steps
You do not need to use all of these. You just need to understand the trend.
Production platforms want:
Standard interfaces
Smaller, auditable components
Reduced privilege
Reproducible builds
Docker can participate in that world, but it no longer owns the whole stage.
A Kubernetes-friendly image build example
If you want a concrete example of the “no Docker daemon” approach, kaniko is a popular choice in cluster-native pipelines.
This is intentionally simplified. In a real setup, you would bring your own workspace, your own auth mechanism, and your own caching strategy. But even in this small example, the idea is visible: build the image where it makes sense, without turning every CI runner into a tiny Docker host.
The practical takeaway for architects and platform teams
If you are designing platforms, the question is not “Should we ban Docker?” The question is “Where does Docker add value, and where does it create unnecessary coupling?”
A simple mental model helps.
Developer laptops benefit from a friendly tool that makes local environments predictable.
CI systems benefit from builder choices that reduce privilege and improve caching.
Production runtimes benefit from standardized interfaces and minimal moving parts.
Docker tends to dominate the first category, participates in the second, and is increasingly optional in the third.
If your team still uses Docker Engine on production hosts, that is not automatically wrong. It might be perfectly fine. The important thing is that you are doing it intentionally, not because “that’s how we’ve always done it.”
Why this is actually a success story
There is a temptation in tech to treat every shift as a funeral.
But Docker moving toward local development is not a collapse. It is a sign that the ecosystem absorbed Docker’s best ideas and made them normal.
The standardization of OCI images, the popularity of Dockerfile workflows, and the expectations around reproducible environments, all of that is Docker’s legacy living in the walls.
Docker is still the tool you reach for when you want to:
start fast
teach someone new
run a realistic stack on a laptop
avoid spending your afternoon installing the same dependencies in three different ways
That is not “less important.” That is foundational.
If anything, Docker’s new role resembles a very specific kind of modern utility.
It is like Visual Studio Code.
Everyone uses it. Everyone argues about it. It is not what you deploy to production, but it is the thing that makes building and testing your work feel sane.
Docker didn’t die.
It just moved to your laptop, brought snacks, and quietly let production run the serious machinery without demanding to be invited to every meeting.